Open-World Image

Generated
Pour tea
Open-World Image

Generated
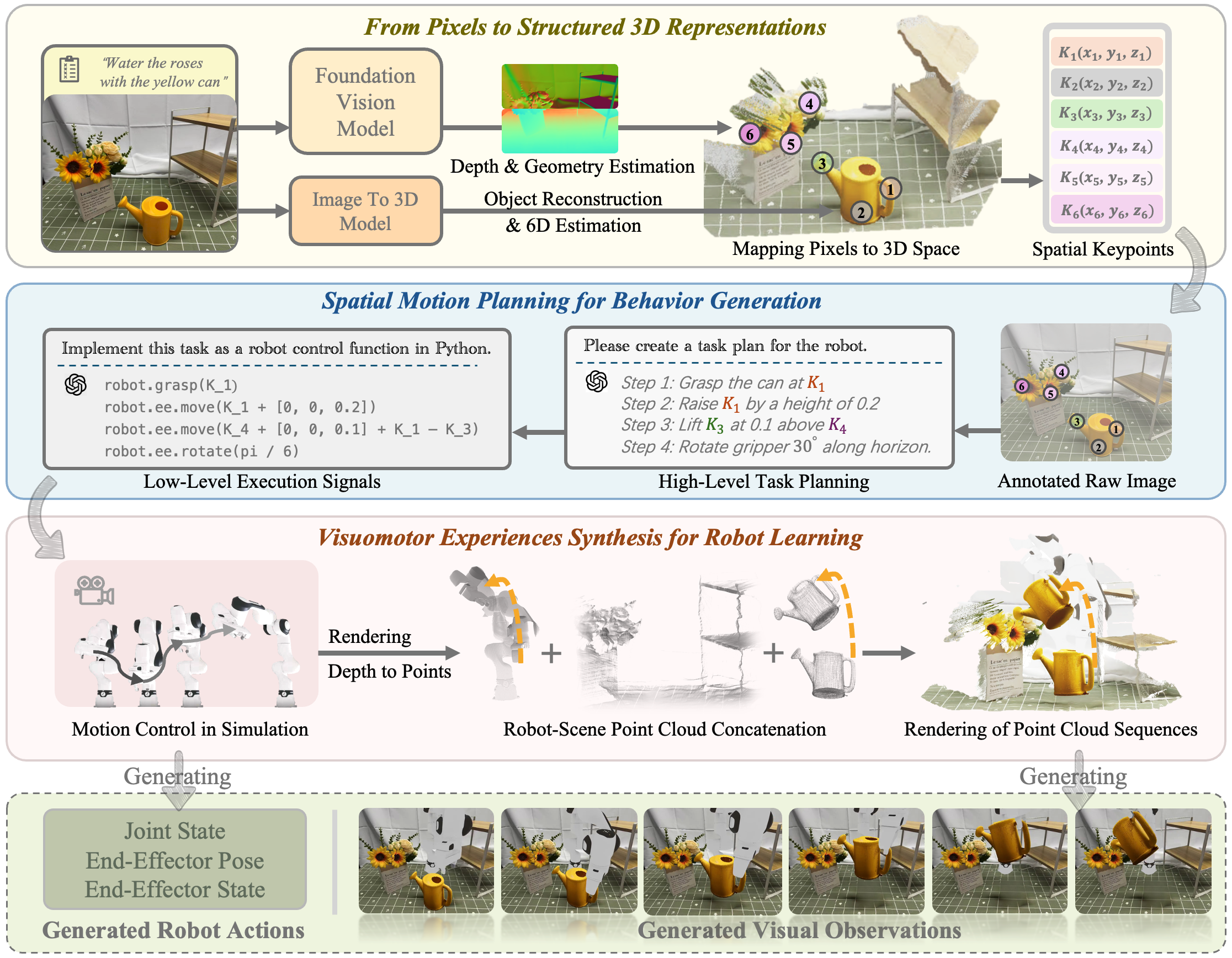
Water the flowers
Open-World Image

Generated
Pick & place
Open-World Image

Generated
Tidy the bedroom
Open-World Image

Generated
Stack rings
Open-World Image

Generated
Place into basket
Click any cell on the right to play the generated trajectory. From a single open-world image (left of each cell), IGen automatically synthesizes the robot trajectory and renders the corresponding visuomotor observations — with no human teleoperation involved.